Lecture 11 Join Algorithms
连接操作
为了防止重复信息等原因 -- 多对多等可能会使用多个表
当我们想要查询信息并进行联合生成有用的查询时 -- 需要join操作
在连接这一点上 关系模型胜出了noSQL
选择合适的连接算法 确定正确的连接顺序 --> 决定查询的关键
this lecture -- 关注一类连接操作 -- binary inner equijoin 二元内等值连接
比较关系中的attribution-- 相等 拼接成新的tuple

设计连接操作符的时候 需要考虑几个决策问题
Decision 1: Output
向其父节点输出了什么内容?
Decision 2: Cost Analysis Criteria
如果推理这些操作的成本
Operator Output: Data
Early Materialization: 早期物化
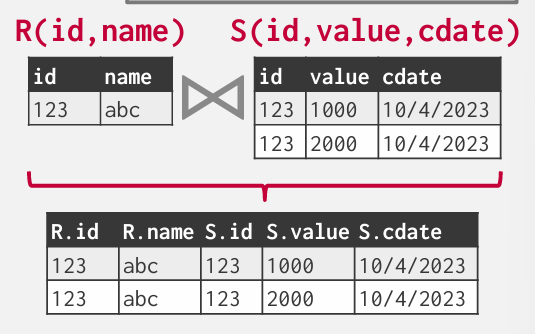
优点就是不需要返回到基本表再次获取数据 -- 只需要一次存储访问 -- 生成的output是所有的attribute
缺点就是如果tuple非常宽,有好多attribute,可能比较糟糕 -- 大量多余的复制 -- 还得投影过滤掉
当然可以把投影操作提前下推 -- 减少部分资源浪费
全部预取 -- 放入bufferpool 可能以后还会用
late Materialization: 延迟雾化
比较之后仅输出record id -- 或类似Postgres中的 tuple id -- 反正就是一个这条数据的唯一标识
然后再投影的时候 还得追溯到基本表
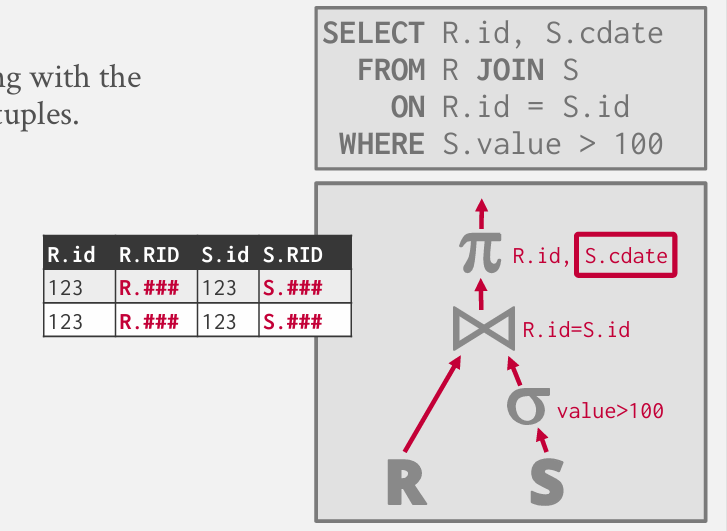
15年前比较普遍
列存储比较流行 因为他本来就得拼
可能需要不断交替处理事务
cost analysis Criteria
如果评估cost?
IO cost
join vs. cross-product(cross join)
cross-product 是创建 笛卡尔积
有点糟糕
因为两个for循环 遍历两个表
today‘s join algorithm
- Nested Loop Join -- 嵌套循环连接
- Sort-Merge Join
Hash Join
在实际应用中 Hash Join 通常是最快的 -- 尤其适用于分析型系统OLAP
OLTP通常不会进行大规模的连接操作 -- 会采用更简单的方法 -- 类似于索引嵌套循环连接
在查询中,如果包含了排序操作 -- 可能会采用排序合并连接算法
MySQL直到2019年才引入哈希连接算法 -- 此前他们主要依赖嵌套循环连接
Nested Loop Join
Naive Nested Loop Join
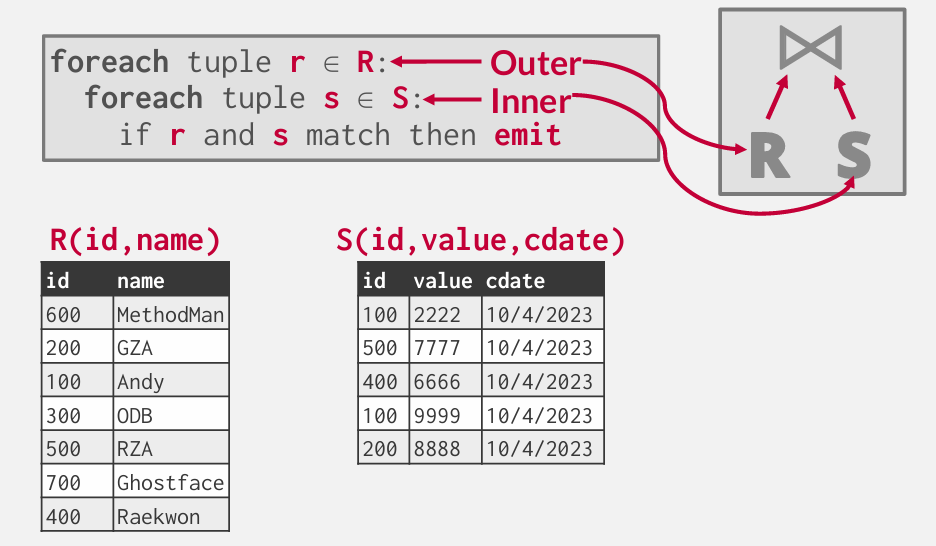
Why is this algorithm bad?
对于每一个tuple in R, it scans S once.
cost: M + (m * N)
Block Nested Loop Join
使用locality(局部性)的概念 -- CSAPP刚学了这个Lecture 11 The Memory Hierarchy

不再针对R中的单独元组进行迭代,也不再逐一遍历整个关系S, 而是仅对R中的每一页进行操作
Cost: M+(M * N)
节省了一部分IO操作
优化器 会用较小的表作为S
If we have B buffers available:
- Use B-2 buffers for each block of the outer table.
- Use one buffer for the inner table. 流式处理内部表
one buffer for ouput.


We can avoid sequential scans by using an index to find inner table matches.
use index
Index Nested Loop Join
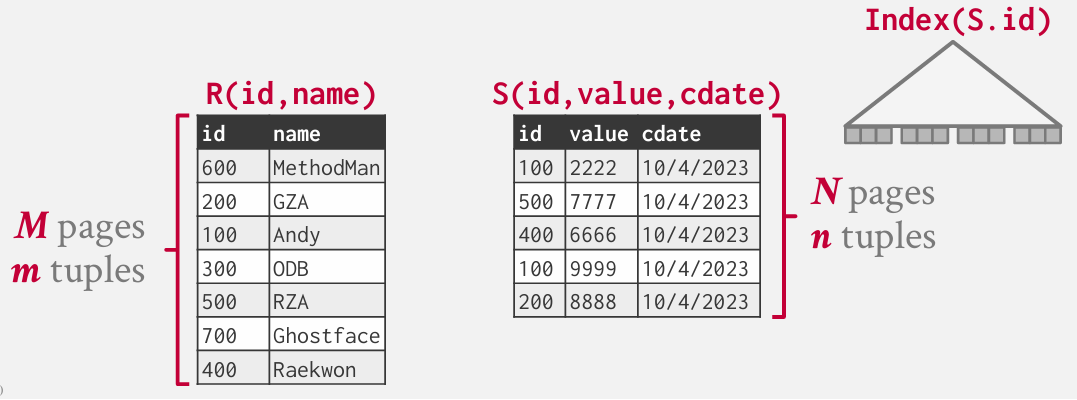
假设我们在SID上建立了索引 -- 我们无需遍历整个内部表 -- 只需要探查索引
假设索引探测的成本是常数C
简化成常数C 是因为 哈希索引和b+tree的成本不一样 不是主键的时候 可能有重复项等等
Cost: M + (m * C)
Sort-Merge Join
Phase1: Sort
给每个表排序
可以使用任何排序算法
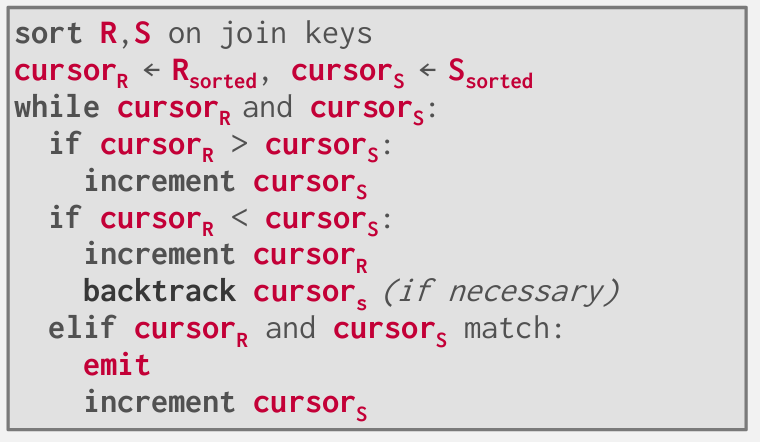
Phase2: Merge
已经拥有了两个排序表 -- 将在每个表创建游标 -- 按照顺序逐一查找匹配项
可以智能的选择跳过
这种排序带来的好处是,当你在外层表上逐行工作时,无需每次都从内层表的起始位置开始
内表需要回溯一丢丢 外表只需要遍历一遍


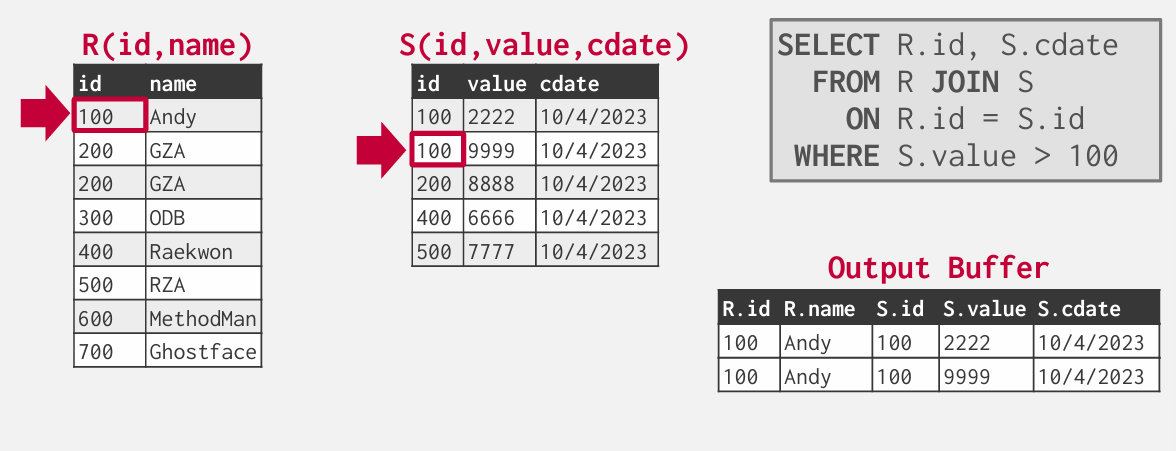
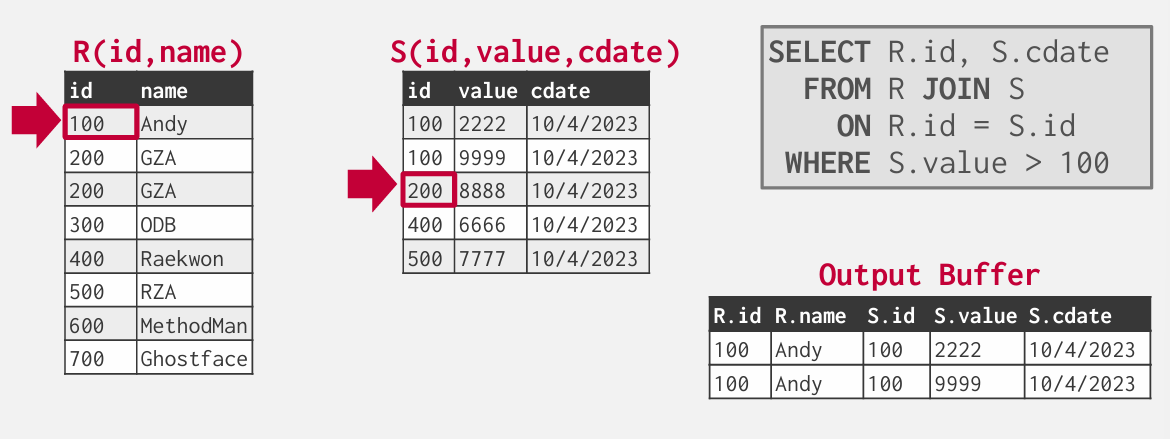

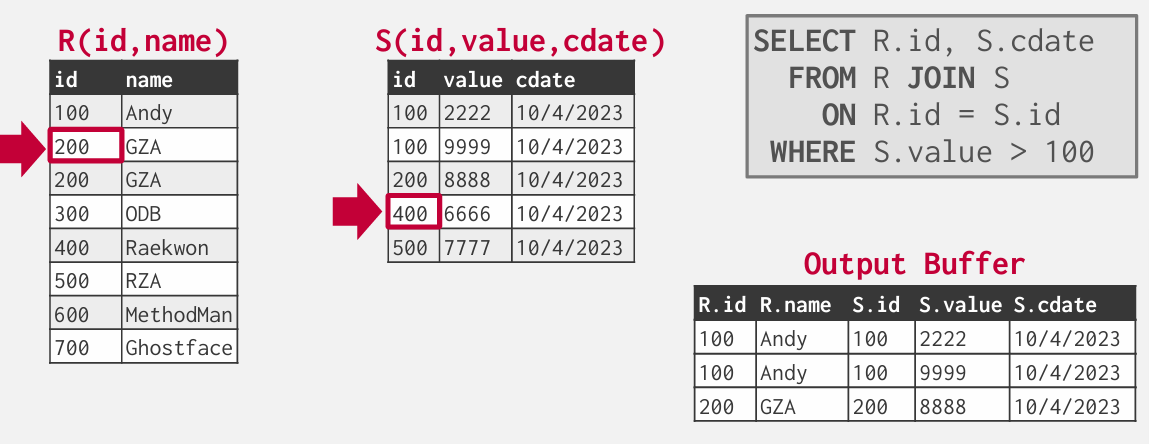
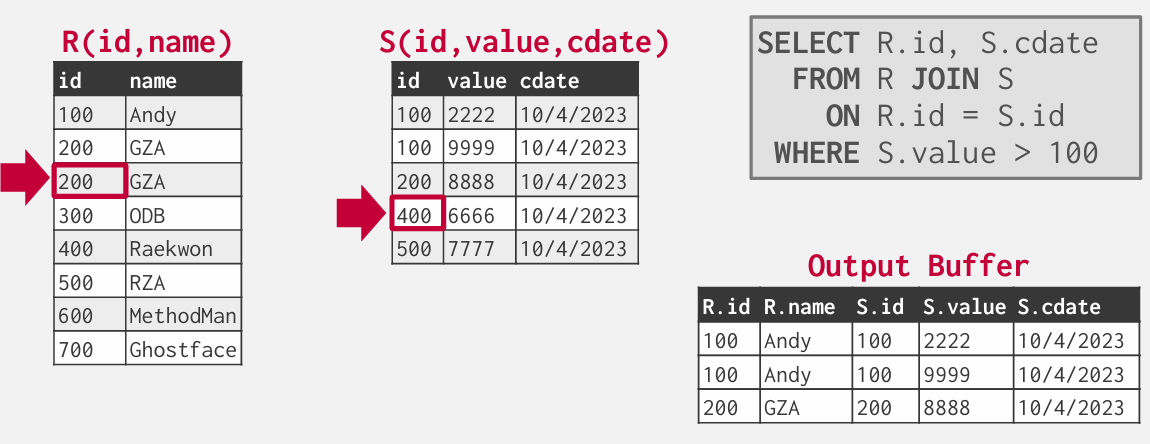
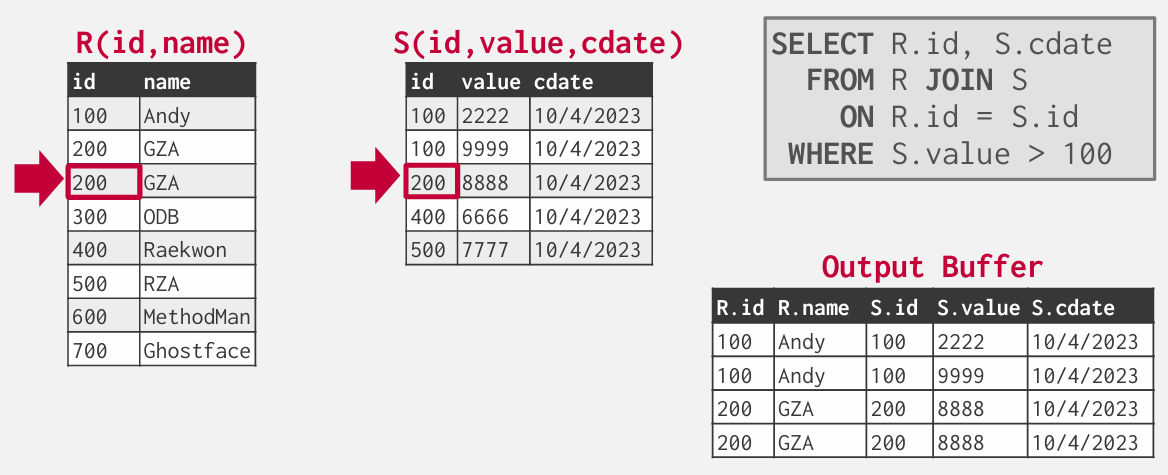
外部表出现重复就要回溯到该index在内部表中首次出现的地方

最坏可能是循环嵌套了
when is sort-merge join useful?
在遇到GROUP BY或类似情况时,数据库系统可能会表示 -- 无论如何都得排序
输入数据已经排序的情况 -- 比如b+tree 索引
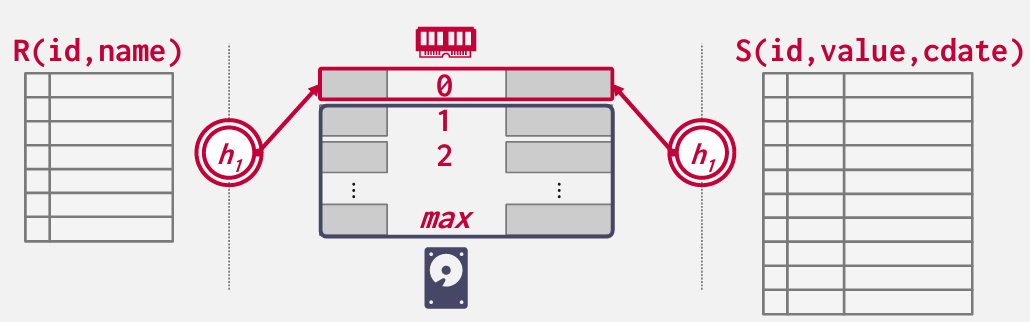
Hash Join
在此依赖的性质是 如果R和S中的两个元组或元组满足连接谓词 如果选择了一个合理的哈希函数 对这些值哈希处理 也会得到相同的哈希值
基本上是在外层表构建一个哈希表 然后使用相同的哈希函数对内部表进行查找
我们主要讨论的是当桶开始溢出 或者哈希表无法完全装入内存时会发生的情况
基本思路是 在一个表上 构建哈希索引 另外一个表上 用哈希函数扫描
Phase1: Build
通常选用线性探测
Phase2: Probe
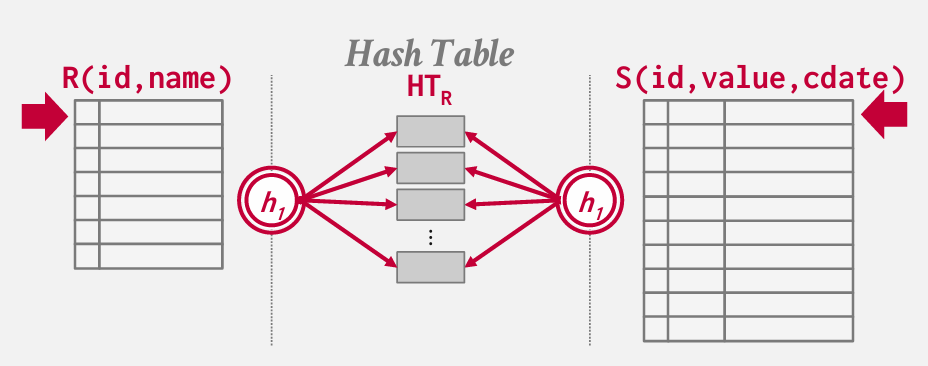
Hash Table Contents
需要保留 Join key 因为可能会发生哈希碰撞
涉及到早期物化和晚期物化 是否将值一同放入哈希表?
Optimization: Probe Filter
探针过滤器技术
依赖于布隆过滤器
基本思路是 在进行哈希查找之前 先看布隆过滤器 确认键是否在哈希表中 因为这是一个小得多的数据结构
可能出现误报 -- 但不会出现假阴性
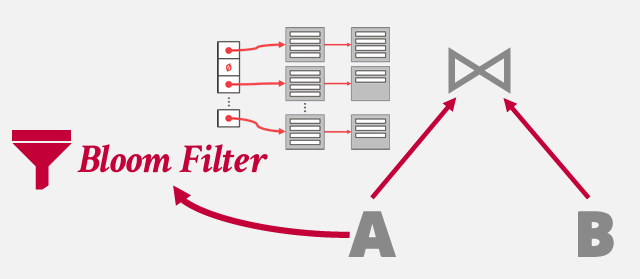
在构建哈希表的时候构建一个Bloom Filter -- 因为 无论如何都得遍历一遍数据
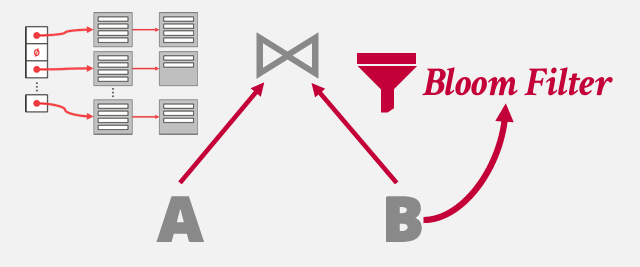
先访问 Bloom Filter
如果不存在 就直接查找下一个
如果存在 再访问哈希表
what happens if we do not have enough memory to fit the entire hash table?
Partition hash join -- 分区哈希算法
专为查询处理的特定硬件?
基本思路是对外表R进行哈希处理 -- 将其映射到一个桶序列中
我们对内表S使用相同的哈希函数来创建自己的存储桶
可以溢出到disk中
每次只需比较一个桶
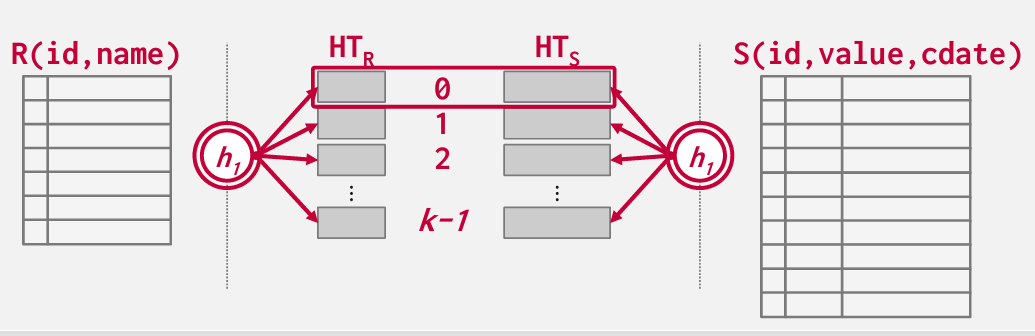
如果分区没法完全放入内存中怎么办?
递归进行划分 -- 你需要对该特定桶选择一个不同的哈希函数 创建更多的桶 然后再对这些数据进行哈希处理 二次散列
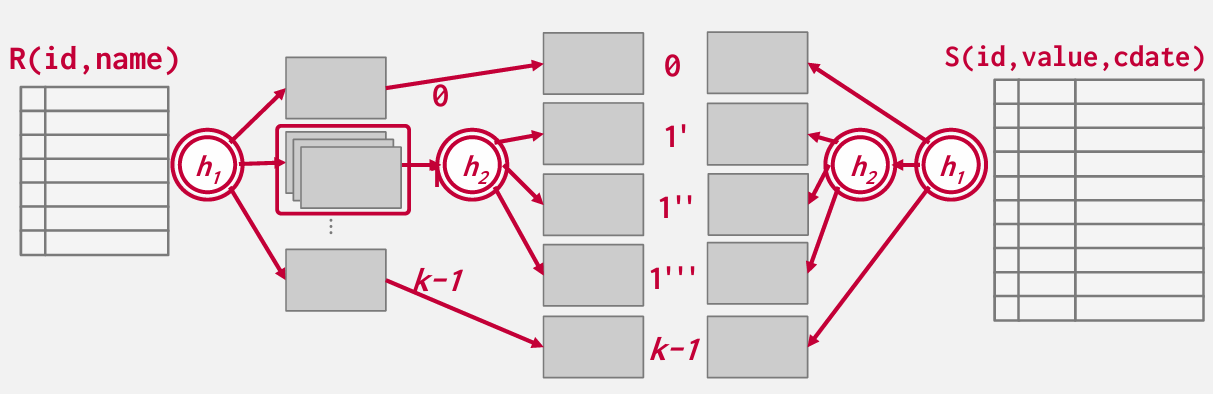
cost of partitioned hash join
最佳情况下 无需递归分区 只需三次遍历每一页

在处理高度偏斜的键值的时候 有一种优化
Hybrid Hash Join
如果键是倾斜的,则 DBMS 会将热分区保留在内存中,并立即执行比较,而不是将其溢出到磁盘。
难以正常工作。在实践中很少这样做